I can’t believe it’s not XML!
As you may or may not have heard, JSON came to Dave Winer’s attention today. He is, quite obviously, of the opinion that this is just a reinvention of what people are already doing just fine with XML, thank you very much, so what’s the point?
Of course, this ignores the fact that the Lisp folks have been making the same argument for years, wondering why there was this great pressing need to go out and invent XML when s-expressions were just dandy.
But once you get past the egos and the attachments to this or that language or tool, the XML/s-expressions debate basically comes down to XML people saying, “OK, you’ve got s-expressions, and they’re pretty cool and they solve your problems. But they don’t solve my problems, so I need something else.”
Not coincidentally, once you get past the egos and the attachments to this or that language or tool, the JSON/XML debate basically comes down to JSON people saying, “OK, you’ve got XML, and it’s pretty cool and it solves your problems. But it doesn’t solve my problems, so I need something else.” Simon has already made some excellent points to this effect.
Just as the Lisp guys couldn’t understand XML — it’s not even an s-expression! — there seem to be a lot of XML folks who can’t understand JSON — yes, Dave, it’s not even XML. I have a theory on why that is, but to explain it I need to go into a couple other things first.
The big belly, revisited
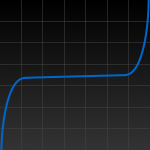
You may remember this little image from the various times I’ve used it; in a very rough way, it represents the rate at which the complexity of your web infrastructure grows with the size and complexity of your web presence. There’s an important lesson in this graph, which I originally summarized like this:
But look at the middle. The graph curves up sharply from the cat-pictures site, taking into account the needs of more complicated and dynamic sites. And at the other end it curves up sharply again, representing the massive expenditure needed to sustain something on the scale of Google. But in the middle it’s almost flat, and it stays almost flat for a long time. These days it’s fashionable to talk about graphs that have a “long tail”, but this one doesn’t: it has a big belly.
Nothing’s changed on that front, really, in the last seven months, so it’s still pretty valid: on one end you have simple flat HTML slapped up on a free hosting site somewhere. On the other end you have mega-multinational corporations with “enterprisey” infrastructure. In between, you have everybody else. The initial spike represents the move from flat HTML to server-side includes or simple PHP or CGI scripts, and through into the belly.
In the belly of the graph, your request/response cycle basically looks like this:
- Request comes in to the web server.
- Web server passes the request along to your application.
- Your application talks to the database for a bit.
- Your application renders a response and kicks it back to the web server.
- The web server passes the response on to the client.
Even as you keep scaling up to ever higher levels of traffic, this basically stays the same; toward the end of the belly, a couple other steps often creep in — load balancing in front of the web server and replication or pooling of multiple database servers — but if you do that smartly it doesn’t really increase your overall complexity that much. And still, you’re doing the same basic things: web server + application code + database.
Of course, eventually you come out into the second spike, where you have things like brokerage systems that run millions of concurrent transactions, or search engines which have to use massively parallel processing to look through ten billion database rows in milliseconds. But most people never come out into that realm, or at least they never really need to but are told otherwise by consultants who can’t get away with charging a thousand bucks an hour just to say, “um, yeah, just slap a load balancer up front, some pooling of DB connections out back and you’re good to go.” Remove them from the picture, and most places that have a web presence will naturally end up in the big, mostly flat belly of the graph.
JSON also naturally fits into that big belly. XML does, too, but it also doesn’t, because I think a lot of this has to do with people using the name “XML” in different ways.
The XMLephant in the room
If the JSON/XML debate were really just about JSON and XML, Dave Winer wouldn’t have written that strange little blog entry. JSON and XML are, after all, just two ways to describe data; which one you use should boil down to mundane things like library support in your language of choice. But Dave revealed what I think is the real source of the debate by mentioning SOAP and XML-RPC, which are hallmarks of the Enterprise Architecture world. In that world it’s just taken for granted that interoperability means implementing (or pretending to implement) about eight zillion different XML-based specifications. So, not XML-the-data-description-format, but XML-the-protocol-stack, which is another beast entirely but which likes to confuse people by never mentioning its full name.
Now, I’m not going to get into whether the folks on the extreme right edge of the graph really need all that stuff just to send text messages to each other (since, really, that’s what’s going on) because that’s not my field (thank heaven). But it is extremely important to know about this and to realize two things:
- A surprising percentage of the time, when people talk about “XML”, they’re really talking about a protocol stack which just happens to use XML-based data formats.
- The Enterprise Architecture world which has basically chained itself to that protocol stack is getting pretty badly shaken up right now by people who are patiently explaining how most of that stack can be replaced with simpler things. This is the REST vs. Web Services debate, and I’m incredibly glad that I don’t have to deal with it.
So the XML-the-protocol-stack people are more than a little bit scared and defensive right now because of the REST folks. And now here are these kids with their startup companies and their weblogs who are getting data exchange and even things that kind of look like APIs out of… JavaScript arrays? The XML guys are sitting up on the mountaintop like the Grinch, with his pile of stolen presents, wondering how Christmas still managed to happen: it came without specs! It came without hype! It came without angle brackets, envelopes or types!
JSON, as a data format, runs fast and loose. The entire format can be exhaustively defined on a single, short page (in fact, it’s exhaustively defined in a little sidebar; everything else is just pretty pictures to make it easier to understand). JSON has about a half-dozen data types, and you can do an awful lot of useful things using just two of them. It doesn’t place very many constraints on how you can use those types; except for two basic rules (the existence of a parent object, and use of strings as keys) it’ll let you stick pretty much anything pretty much anywhere. JSON doesn’t have a formal schema definition language. JSON objects don’t carry around any metadata about themselves.
This is all very frightening to an Enterprise Architect who’s used to data formats which sometimes need as much space to describe the type of data they’re carrying and how they’re carrying it as they need to actually carry the data around. “Real” data formats have specifications and schemas and type checking and gobs and gobs and gobs of metadata. Otherwise, how could they ever work?
The sweet spot
The answer is that JSON works because most people don’t really need all that overhead, and because it’s often possible to do really interesting things with really simple formats. The World Wide Web has been churning along for over a decade with a markup language that originally had no standardized specification; these days it has specs, but they’re almost never enforced and are, in fact, usually thrown down to the ground and trampled upon. And it still works. My bank undoubtedly has a massively complex, strongly-typed system handling my financial transactions, but it shows those transactions to me in a web page which throws sixty-three validation errors if I hit it with a strict parser.
So HTML is a fast and loose format and it doesn’t have any concept of data types that the average programmer would recognize (though it does, in its own special way, have data types), and what rules it has with regards to what you can stick where are routinely ignored. And yet it works. It works really, really well. It works because most people who are using it don’t really need to do complex things with it. Most people who need markup languages for use on the web just want to do simple things like display some text and pictures. You don’t need a 500-page language specification to do that.
JSON is stricter than HTML in some ways; it expects you to obey the rules, but in exchange it gives you fewer rules to follow. And JSON works really, really well. It works because most people who are using it don’t really need to do complex things with it; most people who need data formats for use on the web just want to do simple things like fetch some data from over there and drop it into this web page here. You don’t need the massive overhead of XML-the-protocol-stack to do that.
There are people who genuinely have more complex needs, and I’m not going to try to say whether one thing or another will suit what they’re doing. But for the majority of us who are lounging around in the big belly of the web, JSON is just fine.
The root of the problem
The Enterprise Architecting, XML-as-protocol-stack guys don’t work in the big belly, though. They work, or at least they’ve convinced everyone that they work, way over on the right-hand side of the graph, where the massive infrastructure and insanely complex requirements live. They’ve spent so much time in a highly specialized niche environment that they’ve gotten out of touch with what most of the web is doing, and so they’re having trouble understanding that something which seems to work just fine for them (and I’m being charitable with that description) isn’t going to cut it for everyone else, or that something which would never do for them seems to be working for so many other people.
I think the same basic thing happened with XML and s-expressions; the Lisp folks had gotten so highly specialized on particular problem domains that they were out of touch with what the larger programming world was doing, and so they didn’t realize that something which seemed to be working just fine for them wasn’t going to cut it for everyone else.
And I think that’s where responses like Dave Winer’s come from; JSON’s been kicking around and gaining steam for quite a while now, but it’s never really been on Dave’s radar before. That fact alone says to me that, whatever he’s been up to over the last year or so (I admit to not following Dave’s doings all that closely; I don’t have the time and certain other people do a far better job of it), he’s been in a specialized niche that’s fallen out of touch with the big belly of the web. Whatever he’s doing, SOAP and XML-RPC apparently manage it just fine. If so, good for him, and he should keep right on using them. But they don’t manage things just fine for me (go back and re-read Simon’s post to get hints of some of the problems) and I suspect that they don’t manage things just fine for most of the rest of the web. JSON, on the other hand, does, and so we’ll end up using it or something else in the same vein.
And probably, in time, something new will come along and a bunch of us will hear about it for the first time and sit up and yell, “it’s not even JSON!” In fact, I’m kind of looking forward to that.